
In the field of databases, the popularity of data warehouse products such as Snowflake and Redshift has drawn significant attention from the industry. Recently, two highly anticipated categories in the database field are real-time OLAP databases and streaming databases. Real-time OLAP databases, such as Apache Druid, Apache Pinot, Apache Doris, and ClickHouse, have emerged as outstanding products. On the other hand, streaming databases such as RisingWave, Materialize, DeltaStream, and Timeplus are also representative systems that have gained recognition in recent years.
As a database practitioner, I often encounter discussions regarding the similarities and differences between real-time OLAP databases and streaming databases. These discussions are natural because both categories of products are heading towards “real-time,” provide storage, implement materialized views, and support random queries. With the introduction of concepts such as “unified batch and streaming processing,” “real-time data warehouse,” and “streaming data warehouse,” people are even more confused about the distinctions between these products. This article aims to explore the relationship between these products, the formation of the current pattern, and future development trends from a practical perspective.
The Emergence of Computing Engines

Real-time OLAP engines and stream processing engines were incorporated into the technology stack to provide users with real-time computing capabilities. Real-time OLAP engines cater to the need for low-latency response to user queries, while stream processing engines address the user’s requirement for fresh results.
Let’s travel back ten years ago to the period when big data technology was gradually emerging. At that time, the volume of data in enterprises was skyrocketing, and many companies had to establish their data centers to manage and analyze data. The figure below illustrates the typical technology stack within a company at that time.
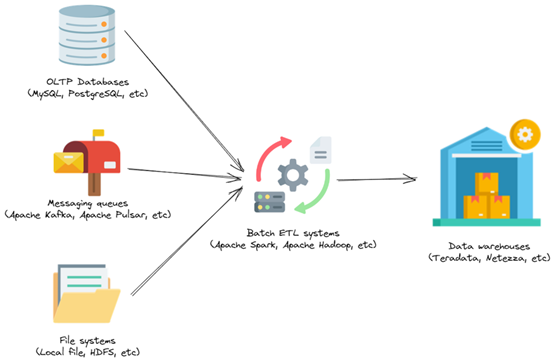
Technology stack within a company ten years ago.
User data was gathered through diverse channels such as OLTP databases (like MySQL and PostgreSQL), messaging systems (like Apache Kafka and Apache Pulsar), and file systems (like local files, HDFS). The ETL system extracted data from these sources every day, and after batch processing, it was imported into the data warehouse. When users needed to analyze historical records, they connected to the data warehouse and performed comprehensive data processing.
The technology stack was effective for most scenarios during that time. However, with the advent of the mobile internet, technology companies’ data requirements continued to evolve. Firms such as Uber and LinkedIn were encountering an explosion in data growth, and the demand for real-time data analysis was surging. The traditional approach of importing data into the data warehouse through batch ETL and querying the data warehouse was no longer suitable. Two primary issues arose as a result.
Firstly, since the data warehouse often needs to perform a complete data scan to accomplish data analysis, it takes a long time from when the user issues the query to when the user receives the results. This results in the inability of users to perform interactive data analytics smoothly on data warehouses using modern BI tools. Human thinking is divergent, and when using interactive UI tools for reporting, users tend to issue multiple random queries continuously to obtain analysis results from different dimensions. However, when the data warehouse responds slowly and takes a long time to return query results, users will experience poor system fluency, which will undoubtedly impact their analysis experience and work efficiency. The development of real-time OLAP engines aims to address this issue. It employs several technologies such as data sharding, vectorized processing, pre-aggregation, and index constructions to ensure that results can be returned to users in ultra-low latency. This enables users to query vast amounts of data in BI systems freely and efficiently, resulting in a significant improvement in their experience.
Secondly, the batch ETL approach caused significant delays in making data queryable from the data source. This problem directly causes users to be unable to make decisions based on the latest results. In enterprises, making real-time decisions based on real-time results can greatly increase profits and reduce costs. In areas such as stock trading, inventory management, and resource monitoring, the decisions people make often have a large deviation depending on the result freshness. To solve this problem, stream processing engines were born. Stream processing engines in the era of big data, such as Apache Storm, Apache Samza, and Apache Flink, were used to support real-time ETL. As long as new data arrives, the stream processing engine triggers computation and directly inserts the computation results into the data warehouse. In this way, new data becomes queryable within a very short period (in seconds or minutes). In some scenarios (such as fraud detection and alarms), users may have the requirement to access query results in real time. To achieve this requirement, users deliver the computation results generated by the stream processing engine to some downstream storage systems and perform random access to the results there.
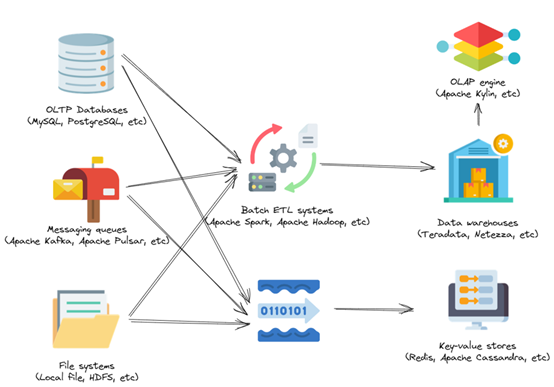
Real-time OLAP engines and stream processing engines were introduced into the enterprises’ technology stack.
As the demands for data processing capabilities of enterprises continue to grow, the technology stack has become increasingly complex. The evolving enterprise technology stack is depicted in the figure above. The incorporation of real-time OLAP engines and stream processing engines can better cater to the enterprise’s real-time requirements.
See also: 22 Top Cloud Database Vendors
From Computing Engines to Databases
Real-time OLAP engines and stream processing engines have gradually evolved into real-time OLAP databases and streaming databases to improve performance, usability, and correctness.
Over the past decade, data processing systems have undergone significant changes, leading to significant changes in system design. Real-time OLAP engines and stream processing engines have gradually evolved into real-time OLAP databases and streaming databases. For instance, Apache Druid, Apache Pinot, and ClickHouse, which were initially used to speed up report queries, have become independent real-time OLAP databases with storage capabilities. In the stream processing engine domain, Apache Flink is also developing its storage system, Apache Flink Table Store, to supplement its storage capabilities. Why have people shifted from “computing engines” to “databases” in these two areas? Is it a coincidence? In fact, this transformation brings a significant improvement in system performance, usability, and correctness.
A computing engine usually doesn’t persist data, which leads to several issues. Firstly, frequent access to external data sources can cause significant performance overhead, resulting in degraded performance. Secondly, users can only utilize the engine for computing, and they need to rely on other systems to access computing results, increasing complexity and inconvenience in operations. Thirdly, each system has its independent correctness guarantee mechanism, and when the computation process involves accessing multiple systems, the correctness of the computation results cannot be guaranteed as a whole. As a result, these two types of computing engines have shifted towards databases to address the above issues. In the following, we will discuss this evolutionary process in detail.
From Real-time OLAP Engines to Real-time OLAP Databases
The original intention of the real-time computing engine was to speed up users’ analytical queries and achieve a low-latency response. Initially, this type of engine needed to continuously extract data from the data warehouse and build indexes and materialized views for the data in the data warehouse to accelerate queries. However, this approach has several drawbacks: the inability to obtain the latest data generated in real-time; some complex queries still need to return to the data warehouse for processing; and the possibility of consistency issues arising from calculation results.
The evolution of real-time computing engines into real-time databases provides solutions to these problems. Real-time databases can not only store data but also ingest data directly from the data source. This means that users can access the latest data in real time while achieving efficient analytical queries. The emergence of real-time databases has greatly improved query performance and simplified user operation processes.
From Stream Processing Engines to Streaming Databases
The main function of stream processing engines is to process data streams in real time and import the processing results into downstream storage systems for user access. However, this architecture is complex, and users hope to integrate the latest data with historical data for comprehensive analysis, making access to external data sources inevitable.
To simplify the architecture and improve performance, stream processing engines have gradually evolved into streaming databases. Streaming databases not only process data streams in real time but also provide persistent storage for data, enabling integrated querying and analysis of real-time and historical data. The emergence of streaming databases enables users to perform real-time queries and analysis directly in a unified system, greatly improving data processing efficiency while reducing user operational complexity.
Differences Between Real-time OLAP Databases and Streaming Databases
Real-time OLAP databases focus on providing low-latency responses to user-initiated queries while streaming databases focus on generating computation results with low latency for pre-defined calculations.
As mentioned earlier, there is some overlap in the use cases of real-time OLAP databases and streaming databases, and they also have many similarities from a technical standpoint: both can store data, provide materialized views, and support random queries. So what are the similarities and differences between these two types of databases?
Real-time OLAP databases and streaming databases are used in different scenarios. Real-time OLAP databases focus on providing interactive real-time responses to users’ random queries while streaming databases generate low-latency computation results for pre-defined computations. In other words, real-time OLAP databases can process random user queries with low latency and are commonly used in interactive reporting, while streaming databases are better suited for pre-defined queries and can incrementally update query results as new data arrives, making them suitable for areas such as alarms and monitoring. Compared to real-time OLAP databases, streaming databases inherit the real-time ETL capabilities of stream processing engines, enabling them to process and deliver data from multiple message sources to downstream data systems after computation.
Despite the considerable technical overlap between real-time OLAP databases and streaming databases, they have significant differences in their current development. Both can provide materialized views, but real-time OLAP databases’ materialized views mainly accelerate random queries, whereas streaming databases’ materialized views mainly define computations and store results. Well-implemented streaming databases, such as RisingWave, usually implement window operations, exact-once semantics, and out-of-order processing, which are not yet supported by any existing real-time OLAP databases. This means that real-time OLAP databases are unsuitable for many stream processing applications. Both real-time OLAP databases and streaming databases support random queries, but real-time OLAP databases use columnar storage and vectorized computation to perform high-speed queries on raw data. In contrast, streaming databases optimize for single-point queries on computation results and currently lack columnar storage, making them inefficient for global scan queries compared to real-time OLAP databases.
The Trends
Real-time OLAP databases and streaming databases are gradually converging from a technical perspective and evolving towards data warehouses. However, this technological development is still several years away, and in the short term, they continue to coexist and provide mutual benefits.
In recent years, the concept of “unified batch and streaming processing” has gained traction in the database field. Many experts advocate for using the same system to unify stream processing and batch processing, which promotes the fusion of real-time OLAP databases and streaming databases. Currently, real-time OLAP databases mainly focus on full table scans, while streaming databases focus on incremental computations. Combining these two computation methods has the potential to significantly simplify the technical architecture within enterprises. I believe this fusion is entirely feasible, as there are no insurmountable contradictions between real-time OLAP databases and streaming databases from a system design perspective. However, the biggest challenge lies in engineering complexity. Developing a stable and high-performance unified batch and streaming system may take at least 3 to 5 years, and whether a product can be widely accepted still requires market validation. In the next few years, I believe that real-time OLAP databases and streaming databases will complement each other rather than simply replace each other.
In addition, two popular terms in the database field are “real-time data warehouses” and “streaming data warehouses.” It is evident that people expect real-time OLAP databases and streaming databases to evolve from “databases” to “data warehouses.” This idea is reasonable because when a system has the ability to store data, why not try to become the place to store the source-of-truth in the enterprise data stack? However, at the current stage, real-time OLAP databases and streaming databases are still far from the standard of data warehouses. The optimization focus of real-time OLAP databases and streaming databases is still on the computing capability, while data warehouses focus more on storage capability optimization and are gradually moving towards the “lakehouse” paradigm. Building an all-in-one system that can incorporate all kinds of advanced technologies can be extremely challenging in terms of both design and implementation.
Conclusion
In conclusion, real-time OLAP databases and streaming databases are two highly anticipated categories in the database field. They have evolved from real-time OLAP engines and stream processing engines, respectively, to provide persistent storage capabilities and support real-time data processing and analysis. Real-time OLAP databases and streaming databases have many similarities and differences. As data requirements continue to evolve, we can expect to see more innovations in these two promising database fields.

Yingjun Wu is the founder of RisingWave Labs, a series-A startup building RisingWave, a distributed SQL database for stream processing. Before running the company, Yingjun was a software engineer at the Redshift team, Amazon Web Services, and a researcher at the Database group, IBM Almaden Research Center. Yingjun received his Ph.D. degree from the National University of Singapore and was a visiting Ph.D. at Carnegie Mellon University. He has been working in the field of stream processing and database systems for over a decade.


